文章汇总
参数的更新,指encoder q的参数,
为encoder k,sampling,monentum encoder 的参数。

值得注意的是对于(b)、(c)这里反向传播只更新,
的更新只依赖于
。
对比学习如同查字典
考虑一个编码查询和一组编码样本
是字典的键。假设字典中只有一个键(记为
)与
匹配。对比损失[29]是指当
与它的正键
相似,且与其他所有键不相似时(认为是
的负键),其值较低的函数。
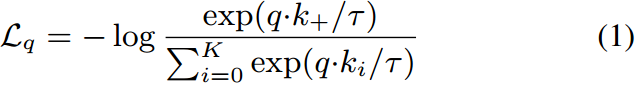
其中 和
可以有多种构造方式。本文使用了一种较为简单的方式:
(1)一种图片进行 random resize;
(2)进行两次224*224的随机Crop得到两个图像分别作为;
(3)进行增强操作,包括 random color jittering, random horizontal flip, random grayscale conversion 等。
一位网友的总结(来源见参考文章)
MoCo的特点是:(1)用于 negative 采样的队列是动态的(2)用于 negative 样本特征提取的编码器与用于query提取的编码器不一致,是一种Momentum更新的关系。而在memory-bank中两个编码器是一致的。(3)与Memory Bank类似,NCE 产生的损失并不影响 ,只影响
。原因是
样本一般是
样本的几倍,更新
的代价很大(例如在 end-to-end中),因此 Memory-Bank 和 MoCo 都不更新
。
摘要
我们提出动量对比(MoCo)用于无监督视觉表征学习。从对比学习[29]作为字典查找的角度出发,我们构建了一个带有队列和移动平均编码器的动态字典。这使得建立一个大的和一致的字典,方便对比无监督学习。MoCo在ImageNet分类的通用线性协议下提供了具有竞争力的结果。更重要的是,MoCo学习到的表征可以很好地转移到下游任务中。在PASCAL VOC、COCO和其他数据集上,MoCo在7个检测/分割任务上的表现优于有监督的预训练对手,有时甚至远远超过它。这表明在许多视觉任务中,无监督和有监督表示学习之间的差距已经很大程度上缩小了。
1. 介绍
无监督表示学习在自然语言处理中非常成功,如GPT[50,51]和BERT[12]所示。但在计算机视觉领域,监督预训练仍然占主导地位,而非监督方法通常落后于此。其原因可能源于它们各自信号空间的差异。语言任务具有离散的信号空间(词,子词单位等),用于构建标记化字典,无监督学习可以基于此。相比之下,计算机视觉则进一步关注字典构建[54,9,5],因为原始信号处于连续的高维空间中,并且不适合人类交流(例如,不像单词)。
最近的几项研究[61,46,36,66,35,56,2]在使用与对比损失相关的方法进行无监督视觉表征学习方面取得了令人鼓舞的结果[29]。尽管受到各种动机的驱动,但这些方法可以被认为是构建动态字典。字典中的“键”(令牌)从数据(例如,图像或补丁)中采样,并由编码器网络表示。无监督学习训练编码器执行字典查找:编码的“查询”应该与其匹配的键相似,而与其他键不同。学习被表述为最小化对比损失[29]。
从这个角度来看,我们假设建立字典是可取的:(i)大,(ii)在训练过程中保持一致。直观地说,更大的字典可以更好地采样底层连续的高维视觉空间,而字典中的键应该由相同或类似的编码器表示,以便它们与查询的比较是一致的。然而,使用对比损耗的现有方法可能在这两个方面中的一个方面受到限制(稍后将在上下文中讨论)。
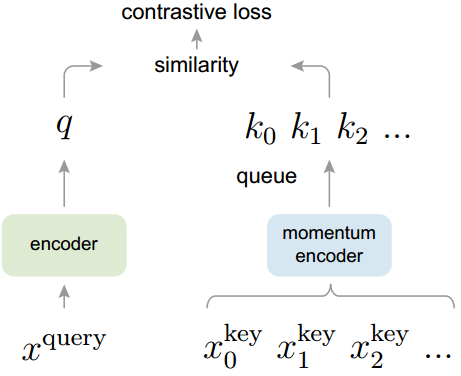
我们提出了动量对比(MoCo)作为一种构建具有对比损失的无监督学习的大型一致字典的方法(图1)。我们将字典维护为数据样本队列:当前小批的编码表示被排队,最老的被排队。队列将字典大小与mini批处理大小解耦,从而允许它很大。此外,由于字典键来自于前面的几个小批量,因此提出了一种缓慢推进的键编码器,作为查询编码器的基于动量的移动平均来实现,以保持一致性。
图1所示。动量对比(MoCo)通过使用对比损失将编码查询q与编码键的字典进行匹配来训练视觉表示编码器。字典键是由一组数据样本动态定义的。字典被构建为一个队列,当前的小批量进入队列,最老的小批量退出队列,将其与小批量大小解耦。键由一个缓慢推进的编码器编码,由查询编码器的动量更新驱动。这种方法为学习视觉表示提供了一个大而一致的字典。
MoCo是一种为对比学习构建动态字典的机制,可用于各种文本预训练任务。在本文中,我们遵循一个简单的实例识别任务[61,63,2]:如果它们是同一图像的编码视图(例如,不同的作物),则查询匹配一个键。使用此借口任务,MoCo在ImageNet数据集的常见线性分类协议下显示了竞争结果[11]。
无监督学习的一个主要目的是预训练表征(即特征),这些表征可以通过微调转移到下游任务。我们表明,在与检测或分割相关的7个下游任务中,MoCo无监督预训练可以超过其ImageNet有监督的对应项,在某些情况下,这一差距非常大。在这些实验中,我们探索了在ImageNet或10亿张Instagram图像集上预训练的MoCo,证明MoCo可以在更真实的、10亿张图像规模和相对未经策划的场景中很好地工作。这些结果表明,MoCo在很大程度上缩小了许多计算机视觉任务中无监督和有监督表示学习之间的差距,并且可以在一些应用中作为ImageNet监督预训练的替代方案。
MoCo是一种为对比学习构建动态字典的机制,可用于各种预序列任务。在本文中,我们遵循一个简单的实例识别任务[61,63,2]:如果它们是同一图像的编码视图(例如,不同的作物),则查询匹配一个键。使用此预训练任务,MoCo在ImageNet数据集的常见线性分类协议下显示了竞争结果[11]。
无监督学习的一个主要目的是预训练表征(即特征),这些表征可以通过微调转移到下游任务。我们表明,在与检测或分割相关的7个下游任务中,MoCo无监督预训练可以超过其ImageNet有监督的对应项,在某些情况下,这一差距非常大。在这些实验中,我们探索了在ImageNet或10亿张Instagram图像集上预训练的MoCo,证明MoCo可以在更真实的、10亿张图像规模和相对未经策划的场景中很好地工作。这些结果表明,MoCo在很大程度上缩小了许多计算机视觉任务中无监督和有监督表示学习之间的差距,并且可以在一些应用中作为ImageNet监督预训练的替代方案。
2. 相关工作
无监督/自监督学习方法一般包括两个方面:预训练任务和损失函数。术语“pretext”意味着要解决的任务不是真正感兴趣的,而是为了学习良好的数据表示而解决的。损失函数通常可以独立于借口任务进行研究。MoCo侧重于损失函数方面。下面我们就这两个方面的相关研究进行讨论。
损失函数
定义损失函数的一种常见方法是测量模型预测与固定目标之间的差异,例如通过L1或L2损失重建输入像素(例如,自编码器),或者通过交叉熵或基于边缘的损失将输入分类为预定义的类别(例如,八个位置[13],颜色箱[64])。其他选择,如下面所述,也是可能的。
对比损失[29]衡量一个表示空间中样本对的相似性。在对比损失公式中,目标可以在训练过程中动态变化,并且可以根据网络计算的数据表示来定义,而不是将输入与固定目标匹配[29]。对比学习是最近几项关于无监督学习的研究的核心[61,46,36,66,35,56,2],我们将在后面的上下文中详细阐述(第3.1节)。
对抗性损失[24]衡量概率分布之间的差异。这是一项广泛成功的技术用于无监督数据生成。表征学习的对抗性方法在[15,16]中进行了探讨。生成对抗网络和噪声对比估计(NCE)之间存在关系(参见[24])[28]。
Pretext tasks
已经提出了各种各样的预训练任务。示例包括在某些损坏情况下恢复输入,例如去噪自编码器[58],上下文自编码器[48]或跨通道自编码器(着色)[64,65]。一些预训练任务形成伪标签,例如,单个(“范例”)图像的变换[17],补丁排序[13,45],跟踪[59]或分割视频中的对象[47],或聚类特征[3,4]。
Contrastive learning vs. pretext tasks
各种pretext任务可以基于某种形式的对比损失函数。实例辨别方法[61]与基于范例的任务[17]和NCE[28]有关。对比预测编码(CPC)[46]中的托辞任务是一种语境自动编码[48],对比多视图编码(CMC)[56]中的托辞任务与着色有关[64]。
3. 方法
3.1. 对比学习如查字典
对比学习[29]及其最近的发展,可以被认为是为字典查找任务训练编码器,如下所述。
考虑一个编码查询和一组编码样本
是字典的键。假设字典中有一个键(记为
)与
匹配。对比损失[29]是指当
与它的正键
相似,且与其他所有键不相似时(认为是
的负键),其值较低的函数。通过点积度量相似性,本文考虑了一种对比损失函数InfoNCE [46]:
其中τ为温度超参数per[61]。和是1个正样本和K个负样本。直观地说,这个损失是试图将q分类为的(K+1)-way基于softmax的分类器的log损失。对比损失函数也可以基于其他形式[29,59,61,36],如基于边际的损失和NCE损失的变体。
对比损失作为无监督目标函数,用于训练表示查询和键的编码器网络[29]。通常,查询表示为,其中
是编码器网络,
是查询样本(同样,
)。它们的实例化取决于特定的预训练任务。输入的
和
可以是图像[29,61,63],补丁[46],或由一组补丁组成的上下文[46]。网络
和
可以是相同的[29,59,63],部分共享的[46,36,2],或者不同的[56]。
3.2. 动量的对比
从上面的角度来看,对比学习是一种在高维连续输入(如图像)上构建离散字典的方法。字典是动态的,因为键是随机采样的,并且键编码器在训练过程中不断发展。我们的假设是,好的特征可以通过一个包含丰富负样本集的大字典来学习,而字典键的编码器尽管在进化中仍尽可能保持一致。基于这一动机,我们提出动量对比,如下所述。
作为队列的字典
我们方法的核心是将字典维护为数据样本队列。这允许我们重用前面小批量的编码密钥。队列的引入将字典大小与小批处理大小解耦。我们的字典大小可以比典型的迷你批处理大小大得多,并且可以灵活和独立地设置为超参数。
字典中的样本逐渐被替换。当前的小批被加入字典队列,队列中最老的小批被删除。字典总是表示所有数据的一个抽样子集,而维护这个字典的额外计算是可管理的。此外,删除最旧的迷你批可能是有益的,因为它的编码密钥是最过时的,因此与最新的密钥最不一致。
动力更新
使用队列可以使字典变大,但它也使得通过反向传播(梯度应该传播到队列中的所有样本)更新密钥编码器变得难以处理。一个比较简单的解决方案是从查询编码器复制键编码器
,忽略这个梯度。但是这个解决方案在实验中产生了很差的结果(第4.1节)。我们假设这种失败是由于快速变化的编码器降低了密钥表示的一致性造成的。我们建议对这一问题进行动量更新。
形式上,将的参数记为
,
的参数记为
,我们将
更新为:
![]()
这里为动量系数。只有参数
通过反向传播更新。Eqn.(2)中的动量更新使得
比
更平滑地演化。因此,尽管队列中的键由不同的编码器编码(在不同的mini-batch中),但这些编码器之间的差异可以很小。在实验中,相对较大的动量(例如m = 0.999,我们的默认值)比较小的动量(例如m = 0.9)要好得多,这表明缓慢发展的密钥编码器是利用队列的核心。
与先前机制的关系
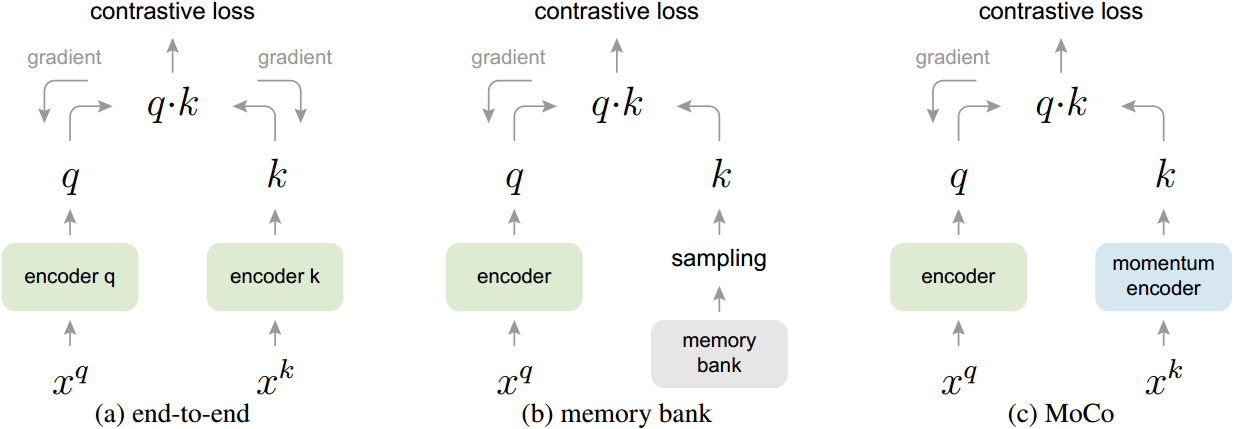
MoCo是使用对比损耗的一般机制。我们将其与图2中现有的两种通用机制进行比较。它们在字典大小和一致性上表现出不同的属性。

图2。三种对比损失机制的概念比较(经验比较见图3和表3)。这里我们举例说明一对查询和键。这三种机制的不同之处在于如何维护密钥以及如何更新密钥编码器。
(a):计算查询和键表示的编码器通过反向传播端到端更新(两个编码器可以不同)。
(b):密钥表示从存储库中采样[61]。
(c): MoCo通过动量更新编码器对新键进行动态编码,并维护一个键队列(未在此图中说明)。
通过反向传播进行的端到端更新是一种自然机制(例如[29,46,36,63,2,35],图2a)。它使用当前迷你批处理中的样本作为字典,因此键被一致地编码(由相同的编码器参数集)。但是字典大小与mini-batch大小相结合,受到GPU内存大小的限制。它也受到大型小批量优化的挑战[25]。最近的一些方法[46,36,2]是基于由局部位置驱动的借口任务,其中多个位置可以使字典大小变大。但这些预训练任务可能需要特殊的网络设计,如修补输入[46]或定制接受域大小[2],这可能会使这些网络向下游任务的转移复杂化。
另一种机制是由[61]提出的记忆库方法(图2b)。内存库由数据集中所有样本的表示组成。每个mini-batch的字典都是从内存库中随机采样的,没有反向传播,因此它可以支持较大的字典大小。然而,一个样本的表示记忆库是在最后一次看到时更新的,所以采样的密钥本质上是关于编码器在过去一个纪元的多个不同步骤,因此不太一致。文献[61]对内存库采用动量更新。它的动量更新是在相同样本的表示上,而不是在编码器上。这个动量更新与我们的方法无关,因为MoCo并没有跟踪每个样本。此外,我们的方法具有更高的内存效率,可以在十亿规模的数据上进行训练,这对于内存库来说是难以处理的。
第4节对这三种机制进行了实证比较。
3.3. Pretext Task
对比学习可以驱动各种各样的pretext任务。由于本文的重点不是设计一个新的pretext任务,我们使用了一个简单的pretext任务,主要是遵循[61]中的实例区分任务,最近的一些研究[63,2]与实例区分任务有关。
根据[61],如果查询和键来自同一图像,我们将其视为正对,否则将其视为负样本对。按照[63,2],我们在随机数据增强的情况下,对同一张图像随机取两个“视图”,形成正对。查询和键分别由它们的编码器和
编码。编码器可以是任何卷积神经网络[39]。
算法1为此提供了MoCo的pretext任务的伪代码。对于当前的小批量,我们对查询及其对应的键进行编码,它们形成正样本对。负样本来自队列。
# f_q, f_k: encoder networks for query and key
# queue: dictionary as a queue of K keys (CxK)
# m: momentum
# t: temperature
f_k.params = f_q.params # initialize
for x in loader: # load a minibatch x with N samples
x_q = aug(x) # a randomly augmented version
x_k = aug(x) # another randomly augmented version
q = f_q.forward(x_q) # queries: NxC
k = f_k.forward(x_k) # keys: NxC
k = k.detach() # no gradient to keys
# positive logits: Nx1
l_pos = bmm(q.view(N,1,C), k.view(N,C,1))
# negative logits: NxK
l_neg = mm(q.view(N,C), queue.view(C,K))
# logits: Nx(1+K)
logits = cat([l_pos, l_neg], dim=1)
# contrastive loss, Eqn.(1)
labels = zeros(N) # positives are the 0-th
loss = CrossEntropyLoss(logits/t, labels)
# SGD update: query network
loss.backward()
update(f_q.params)
# momentum update: key network
f_k.params = m*f_k.params+(1-m)*f_q.params
# update dictionary
enqueue(queue, k) # enqueue the current minibatch
dequeue(queue) # dequeue the earliest minibatch
# bmm: batch matrix multiplication; mm: matrix multiplication; cat: concatenation.
技术细节
我们采用ResNet[33]作为编码器,其最后一个全连接层(经过全局平均池化)具有固定维输出(128-D[61])。该输出向量由L2范数归一化[61]。这是查询或键的表示形式。设Eqn.(1)中的温度τ为0.07[61]。数据增强设置如下[61]:从随机调整大小的图像中截取224×224-pixel裁剪,然后经历随机颜色抖动,随机水平翻转和随机灰度转换,这些都可以在PyTorch的torchvision包中使用。
洗牌BN
我们的编码器和
都与标准ResNet[33]一样具有批处理归一化(BN)[37]。在实验中,我们发现使用BN会阻止模型学习良好的表示,正如[35]中类似的报道(避免使用BN)。该模型似乎“欺骗”了pretext任务,并很容易找到低损失的解决方案。这可能是因为样品之间的批内通信(由BN引起)泄露了信息。
我们通过变换BN来解决这个问题。我们使用多个GPU进行训练,并对每个GPU的样本独立执行BN(如常见实践所做的那样)。对于密钥编码器,我们在当前的小批量中打乱采样顺序,然后将其分配给gpu(并在编码后打乱);查询编码器
的小批量示例顺序没有改变。这确保了用于计算查询及其正键的批统计信息来自两个不同的子集。这有效地解决了作弊问题,并使培训受益于BN。
我们在我们的方法和其端到端消融对应的方法中都使用了洗牌BN(图2a)。它与对应的内存库无关(图2b),后者不受此问题的影响,因为正键过去来自不同的小批量。
4. 实验
使用 MoCo 进行无监督训练后,固定网络不变,在其后增加一个线性层+SoftMax进行分类。后面的线性层和 softmax 是需要进行训练的。下图的结果中,随着负样本采样个数的增大准确率不断提升,且MoCo明显优于 End-to-End 和 Memory Bank 的方法。


表1。ImageNet上线性分类协议下的比较。这个图形使这张表形象化了。所有这些都在ImageNet-1M训练集上进行无监督预训练,然后在冻结特征上进行有监督线性分类,在验证集上进行评估。参数计数是特征提取器的参数计数。如果可用,我们将与改进的重新实现进行比较(在数字后面引用)。
注:R101∗/R170∗为去掉最后残差级的ResNet-101/170 [14,46,35], R170变宽[35];Rv50为可逆网[23],RX50为ResNeXt-50-32×8d[62]。
5. 讨论与结论
我们的方法在各种计算机视觉任务和数据集中显示了无监督学习的积极结果。有几个悬而未决的问题值得讨论。MoCo从IN-1M到IG-1B的改进一直很明显,但相对较小,这表明更大规模的数据可能没有得到充分利用。我们希望一个先进的pretext任务将改善这一点。除了简单的实例识别任务[61]外,还可以将MoCo用于伪装自编码等借口任务,例如语言[12]和视觉[46]。我们希望MoCo对其他涉及对比学习的pretext任务有用。
参考资料
论文下载(CVPR 2020)
https://arxiv.org/abs/1911.05722

代码地址
GitHub - facebookresearch/moco: PyTorch implementation of MoCo: https://arxiv.org/abs/1911.05722
参考文章
MoCo: Momentum Contrast 无监督学习 - 知乎